
| NEWS (04/05/25) |
|
Webページのテキスト文字列のみを抽出・保存できるIEプラグイン「getHTMLT」
ニュースサイトなどで記事部分のみをスクラップブックにしたいときに便利
|
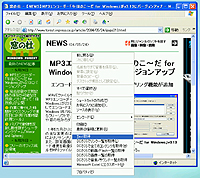
| 「getHTMLT」v1.0.0 |
「getHTMLT」は、IEで表示しているWebページ内のテキスト文字列のみを抽出し、テキストファイルとして保存できるIEプラグイン。ニュースサイトなどで記事部分のみをスクラップブックとして保存したいときに利用できる。
インストールすると追加されるIEの右クリックメニュー[Text取得]を、取得したいテキストの表示されているWebページ上で実行すると、インストール時に指定した保存先フォルダ内に、Webページ内のテキスト文字列のみを抽出したテキストファイルが作成される。
作成したテキストは、タイトルバーの文字列をファイル名にして保存。なお、フレームが含まれるページでは、右クリックメニューを表示しているフレーム内のテキストのみ抽出する仕組みだ。
ニュースサイトなどで記事部分のみをスクラップブックにしたいときや、レイアウトなどにこだわらずにWebページの内容を保存したいときなどは、本ソフトを利用してみてはどうだろうか。
【著作権者】丸干商店
【対応OS】Windows 98/Me/2000/XP
【ソフト種別】フリーソフト
【バージョン】1.0.0(04/05/19)
□丸干商店ページ
http://hp.vector.co.jp/authors/VA031375/
(小津 智幸)
|
|
||||
|
 トップページへ
トップページへCopyright (c) 2004 Impress Corporation All rights reserved.
編集部への連絡は
 まで
まで