ニュース
Google、新しい埋め込みモデル「Gemini Embedding 2」をパブリックプレビュー【4月23日追記】
4月22日付で一般提供に。画像も動画も音声も、ネイティブでマルチモーダル
2026年3月11日 09:50

米Googleは3月10日(現地時間)、「Gemini Embedding 2」を発表した。パブリックプレビューとして「Gemini API」や「Vertex AI」で提供される。
「Gemini Embedding 2」は、同社のAI部門Google DeepMindによる新しい“埋め込み”モデル。埋め込み(embedding)とはデータの特徴をベクトル(数値配列)に変換してそれぞれの類似性を比較・計算できるようにする手法で、RAG(Retrieval-Augmented Generation:検索拡張生成)やセマンティック検索(キーワードマッチではなく、意味や関連性をもとにする検索)、感情分析、データクラスタリング(データのグループ化)などに用いられる。

先代の「Gemini Embedding」はテキスト埋め込みモデルだったが、今回発表された2世代目はネイティブでマルチモーダルなのが特徴だ。テキストだけでなく、画像、音声、動画、PDFドキュメントなども単一の埋め込み空間にマッピングできる。100を超える言語を意味的に捉えられるほか、テキストや画像といった複数のモダリティを混在入力することも可能だ。
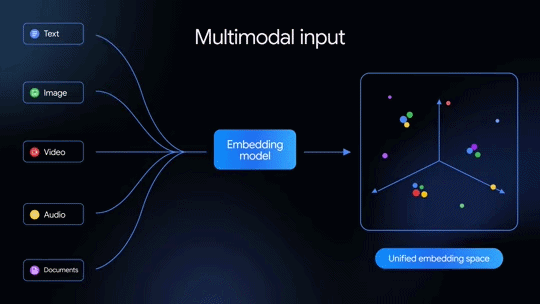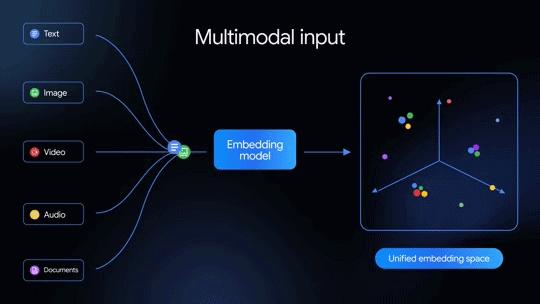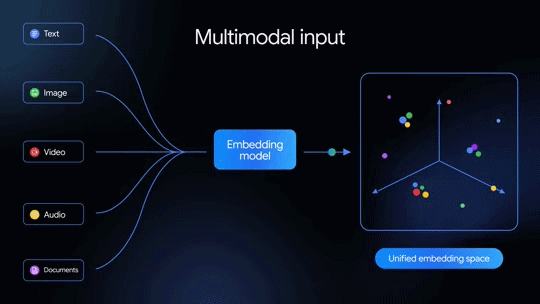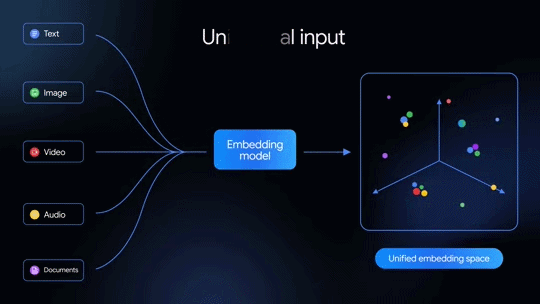
本モデルは「Gemini」をベースとしており、以下をサポートする。
- テキスト:最大8,192の入力トークン
- 画像:最大6枚(PNG/JPEG)
- 動画:最大120秒(MP4/MOV)
- 音声:文字起こしなしに直接埋め込み可能
- ドキュメント:最大6ページのPDFドキュメント
これまでの埋め込みモデルと同様、「Gemini Embedding 2」はマトリョーシカ表現学習(MRL)を採用しており、次元を動的に縮小して情報を「ネスト」(入れ子)にする。これにより既定の3,072から柔軟に出力次元を縮小できるため、開発者は性能とストレージコストのバランスを自由に調整できる(最高品質を得るには3,072、1,536、768次元の利用が推奨)。
「Gemini Embedding 2」はテキスト、画像、動画、音声の各タスクで既存モデルを上回る性能を実現している。とくに音声理解では大幅な進歩を遂げており、マルチモーダル性能で新しい標準を打ち立てたと謳っている。
[2026年4月23日編集部追記] 4月22日付で「Gemini Embedding 2」が一般提供となったことがアナウンスされた。現在Gemini APIとVertex AIを介して利用できる。
