ニュース
Google、最先端の画像モデル「Gemini 2.5 Flash Image」を発表
同じプロンプトで同じキャラを一貫生成、画像の編集や結合して馴染ませる処理も得意
2025年8月27日 08:10

米Googleは8月26日(現地時間)、「Gemini 2.5 Flash Image」(nano-banana)を発表した。「Gemini 2.5 Flash」はもともと画像生成をネイティブサポートしているが、いくつかの点を改善して、より画像生成に特化させたのが「Gemini 2.5 Flash Image」だ。

キャラクターの一貫性を維持
画像生成AIの基本的な課題として、同じプロンプトを与えたにもかかわらず、画質やディテールなどの結果が生成のたびに若干異なってしまうという点がある。これは詳細なプロンプトを与えたり、生成プロセスを微調整することで改善はできるが、特定のキャラクターを異なる環境に配置したり、キャラクターの特徴を保ったまま表情や服装のバリエーションを作ったりしたい場合にはしばしば問題となる。
「Gemini 2.5 Flash Image」はこの点が改善されており、同じプロンプトであればほぼ同じキャラクターが一貫して生成される。また、ビジュアルテンプレートを適用するのも得意で、さまざまな制服に着替えさせたり、異なるポーズをさせたりといったデザインにさまざまな人物を落とし込むといったこともできる。

プロンプトベースの画像編集
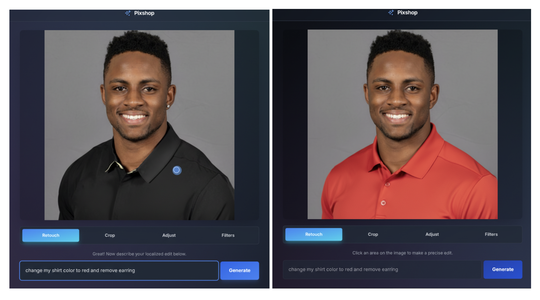
「Gemini 2.5 Flash Image」は、自然言語でターゲットを絞った画像の変換も得意だ。たとえば画像の背景をぼかしたり、Tシャツの汚れを取り除いたり、写真から人物全体を削除したり、被写体のポーズを変更したり、白黒写真に色を追加したり……といった加工を言葉で説明すれば、モデルはそれに応じた編集や加工を行ってくれる。
ネイティブワールドの知識
多くの画像生成AIはすぐれた画像を出力するが、一般に現実世界に対する理解が欠けている。その点、「Gemini 2.5 Flash Image」は「Gemini」譲りの知識を持っており、現実世界の理解に即した画像生成が行える。
たとえば手書きの問題図を読み取って理解し、それを解き明かし、結果を図に書き加えて出力するといったことも可能。つまり、教育用途にも活用できる。これは従来の画像生成AIには難しかったことだ。

マルチイメージフュージョン
さらに、「Gemini 2.5 Flash Image」は複数の入力画像を理解して、結合するのも得意だ。オブジェクトをシーンに配置して、周りの景色に馴染ませるといった処理も簡単に行える。

SynthID
「Gemini 2.5 Flash Image」で作成または編集されたすべての画像には、不可視の「SynthID」デジタル透かしが含まれる。そのため、AIが生成または編集したものであることが簡単に識別できる。
可用性
「Gemini 2.5 Flash Image」は同日より、「Gemini API」と「Google AI Studio」を介してプレビュー提供される。今後数週間で安定版に達する見込みだ。価格は100万出力トークンあたり30.00米ドルで、それぞれの画像は1,290出力トークンを要する(つまり1画像あたり0.039米ドル)。そのほかのモダリティ(テキストの処理など)に関しては「Gemini 2.5 Flash」の価格と同じだ。
今後は長文テキストのレンダリング、一貫性の向上、画像のディテール表現の改善などに取り組んでいくとのこと。
